Label Studio and Heartex AI Platform
Opensource tool for data labeling and AI platform [2019-today]Our platform helps you create better models in a shorter time. Annotate, label and explore your datasets using our opensource tool, making it ready for machine learning.

Speech recognition solutions
Language and speaker identification, diarization [2011]I have a lot of R&D projects at ASM Solutions. Tensorflow, PyTorch, GMMs, iVector, FBanks, etc are widely used in my daily practice. I visit international conferences in this area and have publications there. All researches are run under Python and C++. Also we develop a speech processing SDK and make high performance computing solutions with CUDA.
TfMicro: Lightweight framework for Tensorflow
Build your tf models comfortably [2017-today]
Focus only on creating your TF model. All the rest TfMicro will be done for you.
Multiprocessing data template, callbacks, keyboard operations, saving/loading/preloading models and much more.
TfMicro

Testarium: Research tool, open source
Research tool to perform experiments and store resultsas in the repository [2014-today]
It implements scientific template of experiments and uses numpy, colorama, flask, d3, jquery-ui and angular to provide powerful shell and beautiful presentation of your experimental data and scores.
It can be helpful for science researchers and their managers to monitor the work progress and to optimize parameters. I use it in my work with neural networks, speech recognition tasks and others. Go to testarium.makseq.com.
ECG Demodulator and iOS/Android Mobile App
FM Demodulator for the electrocardiogram signals (ECG) [2013-2014]iOS/Android mobile app for ECG recording and management [2014-2015]
FM demodulator software for ECG was specially disigned for BIOSS ECG devices by me. It's used by KardioDom in the healthcare application HelterBook.
Later I designed and developed with my team iOS / Android application for KardioDom based on this demodulator. Go to App Store
Publications
Here is the list of my scientific publications (part of them are in russian only):- Lightweight embeddings for speaker verification. Maxim Tkachenko, Alexander Yamshinin, Mikhail Kotov. Speecom, 2018 link
- Speech Enhancement for Speaker Recognition Using Deep Recurrent Neural Networks. Maxim Tkachenko, Alexander Yamshinin, Nikolay Luibimov, Mikhail Kotov. Speecom, 2017 link
- Language Identification using Time Delay Neural Network D-Vector on Short Utterances. Maxim Tkachenko, Alexander Yamshinin, Nikolay Luibimov, Mikhail Kotov. Speecom, 2016 link
- Danila Doroshin, Alexander Yamshinin, Nikolay Lubimov, Maxim Tkachenko. Shared latent subspace modelling within Gaussian-Binary Restricted Boltzmann Machines for NIST i-Vector Challenge 2014. Interspeech, 2015 link
- Danila Doroshin, Maxim Tkachenko, Nikolay Lubimov, Mikhail Kotov. Application of l_1 Estimation of Gaussian Mixture Model Parameters for Language Identification. Speech and Computer Lecture Notes in Computer Science Volume 8113, 2013, pp 41-45 link
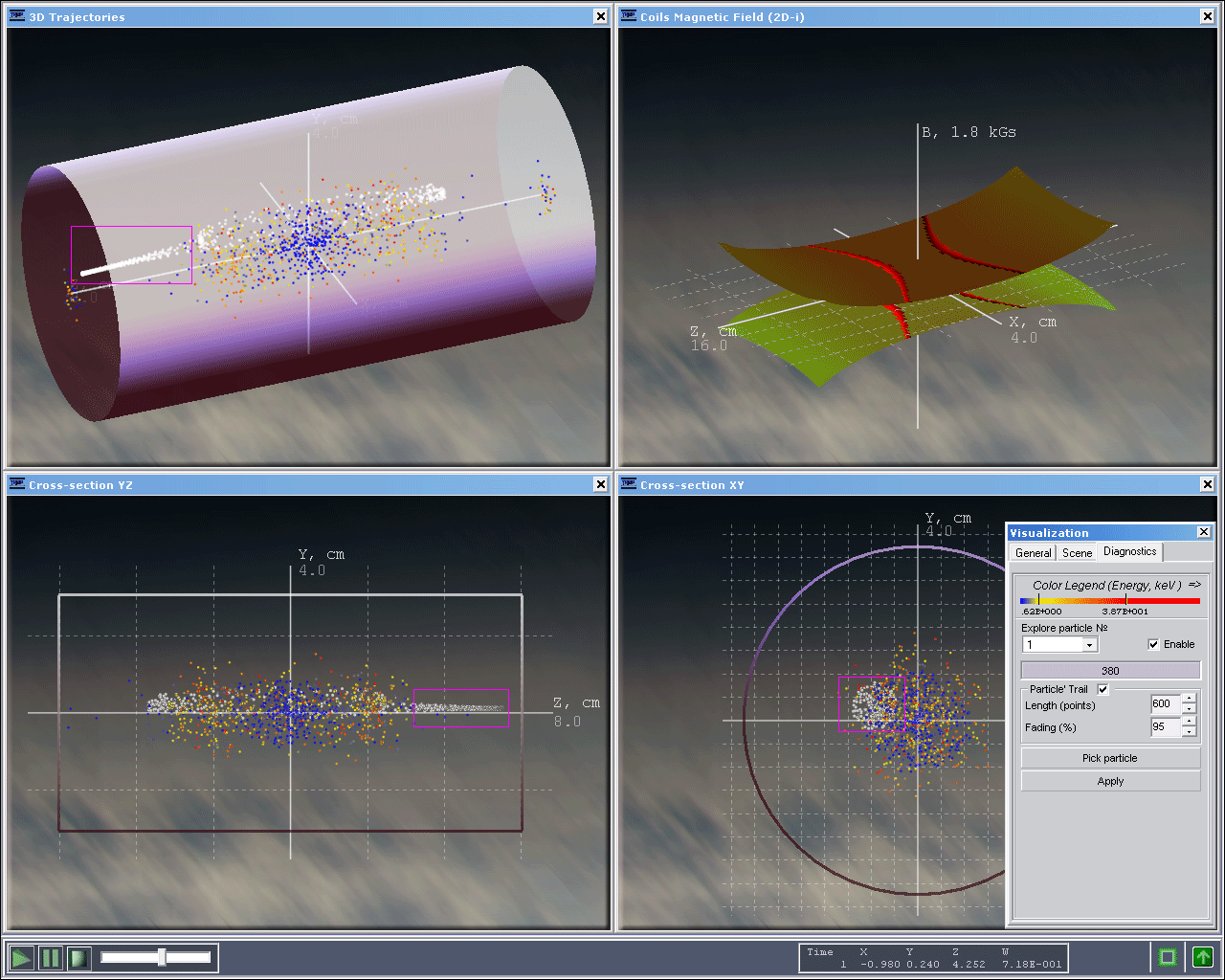
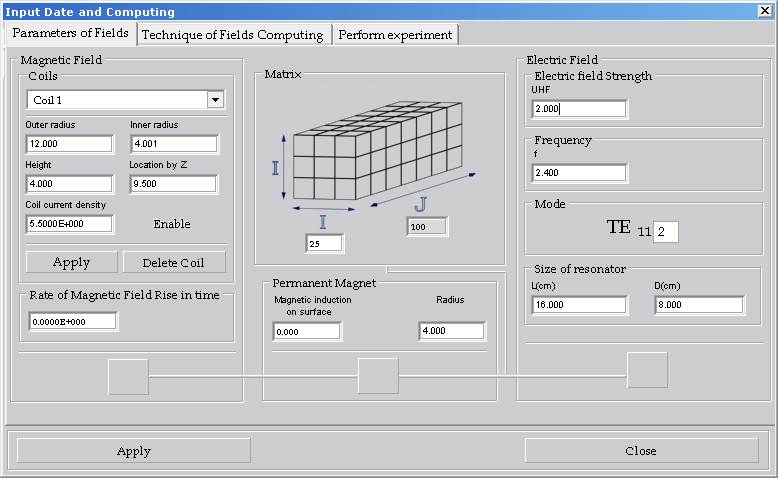
- Maxim S. Tkachenko. Modeling Environment for Particles Configuration Control in Magnetic and Electric Fields. Intel International Science and Engineering Fair. Phoenix, 2005 Read more
Loopseque/MovBeats. Audio/Video sequencers for iOS
Loopseque - audio sequencer for iOS [2010-2012]MovBeats - video sequencer for iOS [2011-2012]
Maths and programming of audio processing, sound engine architecture, concept & ideas generation, audio routing scheme, some of UI programming, asm maths optimizations for ARMv6 processors - all of them were mine.
MovBeats is using my audio engine from Loopseque with little changes in audio routing scheme.



MovBeats official web site
Adaptive noise reduction system based on multi-resolution FFT
Online audio denoising service [2007-2009]My master graduate work became an online service further. But now I have stopped support and closed the service.

Tool for plasma modeling and visualizing
Modeling Environment for Particles Configuration Controlin Magnetic and Electric Fields [2003-2006]
My first R&D work achieved the third award at Intel ISEF.
You can download it here (Win x86)